COMUNICACIÓN POSTER
AUTORES
Delgado Hernández, Jonathan 1; Hernández Pérez, Miguel Angel 2; Abreu Rodríguez, Rossana Teresa 2; Betancort Montesinos, Moises 3
CENTROS
1. Servicio: Logopedia. Universidad de La Laguna; 2. Servicio de Neurología. Complejo Hospital Universitario Nuestra Sra. de Candelaria; 3. Servicio: .
OBJETIVOS
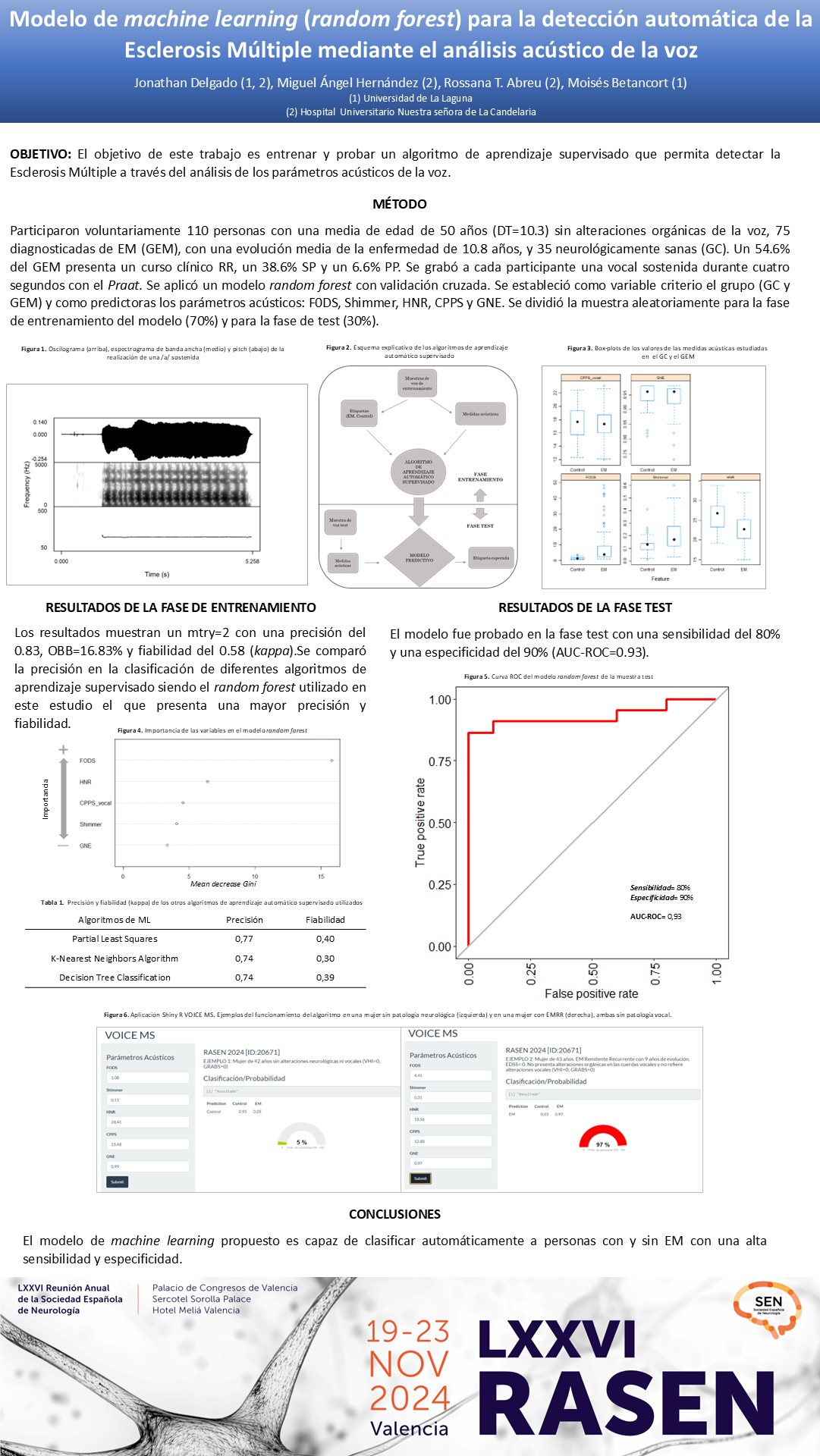
El objetivo de este trabajo es entrenar y probar un algoritmo de aprendizaje supervisado que permita detectar la EM a través del análisis de los parámetros acústicos de la voz.
MATERIAL Y MÉTODOS
Participaron voluntariamente 110 personas con una media de edad de 50 años (DT=10.3) sin alteraciones orgánicas de la voz, 75 diagnosticadas de EM (GEM), con una evolución media de la enfermedad de 10.8 años, y 35 neurológicamente sanas (GC). Un 54.6% del GEM presenta un curso clínico RR, un 38.6% SP y un 6.6% PP. Se grabó a cada participante una vocal sostenida durante cuatro segundos con el Praat.
RESULTADOS
Se aplicó un modelo random forest con validación cruzada. Se estableció como variable criterio el grupo (GC y GEM) y como predictoras los parámetros acústicos: F0DS, Shimmer, HNR, CPPS y GNE. Se dividió la muestra aleatoriamente para la fase de entrenamiento del modelo (70%) y para la fase de test (30%). Los resultados muestran un mtry=2 con una precisión del 0.83, OBB=16.83% y fiabilidad del 0.58 (kappa). El modelo fue probado en la fase test con una sensibilidad del 80% y una especificidad del 90% (AUC-ROC=0.93). Se comparó la precisión en la clasificación de diferentes algoritmos de aprendizaje supervisado (Parcial Least Squares, Random Forest, K-Nearest Neighbors algorithm y decision tree clasiffication) siendo el random forest utilizado en este estudio el que presenta una mayor precisión y fiabilidad.
CONCLUSIONES
El modelo de machine learning propuesto es capaz de clasificar automáticamente a personas con y sin EM con una alta sensibilidad y especificidad.